
Bulletin#E3A0AD255B51851AE075CEE3C5C4ED4F
orCmWKnKpoNGs5gJXA3tkxwWKv8j8KYxxp#2320
@2023-09-10 16:00:00
orCmWKnKpoNGs5gJXA3tkxwWKv8j8KYxxp#2320
@2023-09-10 16:00:00

# 芯片正面战场,AI第二战场
原创 土曹 [ 新潮沉思录 ](javascript:void\(0\);)
__ _ _ _ _

文 | 土曹 新华门的卡夫卡
大型语言模型(简称“大模型”)是生成式人工智能的技术核心和成功关键,也正成为大国科技创新的新竞技场。在国内,目前已有多家大模型通过备案,正式面向公众开放。
上周四(9月7日),世界顶级开源大模型Falcon发布了1800亿参数的180B版本,而同一天,腾讯也亮相了其超千亿参数规模的自研大模型“混元”。

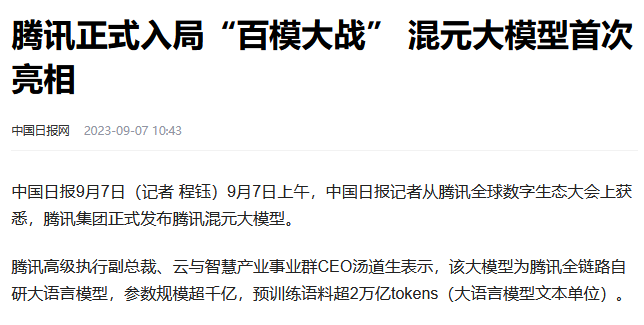
大模型这条赛道在年初时,OpenAI犹如单骑闯关、一骑绝尘,在有心人的刻意渲染下,简直成为了中国体制的“斯普特尼克时刻”,然而经过半年多的时间的奋起直追,国内大模型研发如今已然形成百舸争流的局面,诸多中国公司的大模型千帆竞发、羽翼齐飞,展现了我国强劲有力的工程科学技术人才(即近几年反复提及的STEM)供给,以及中国的科技产业界强烈的进取心与追赶意识。
如果说,年初某些有心人渲染OpenAI的技术成就是刻意制造“中国的斯普特尼克时刻”来达成其不可告人的政治目的,那么中国本身的技术实力和储备厚度仿佛50年代的美国一样奋起直追,
** “真成了斯普特尼克”了,恐怕反而是这些人不愿意看到的。 **
前几天,在雷蒙多访华期间,华为以一种“歼二十不宣而告的首飞”的模式发布了基于“绕开美国管制和制裁”的产业链和技术储备研发的集成了卫星通行功能的新一代终端(可能说手机已经不完全准确了)mate
60 pro,大涨国人的士气。

如果说这是因为华为的突围是属于“正面击溃坂田联队”,击破了帝国主义的封锁,那么近期的国产大模型“百模竞流”, **
就是“开辟第二战场”了,动摇了原本对手认为暂时安全的后方。 **
毕竟,年初OpenAI成为“当红炸子鸡”的时候,那些人可是在拿“领先中国业界五到十年”来刻意渲染的。
### ** 大模型和芯片:软硬互为支撑的体系 **
大模型的基本目标是: ** 说人话、懂人话、能回答问题,并尽量减少常识错误。 **
其中,说人话是生成式人工智能最重要的目标,对应的设计思想是:从人类规模语料中自动提取关键性语言痕迹,并用于语言的自动生成。无论是人类的语言习惯,还是人类智力功能在语言中的运用,都会留下语言痕迹,这些痕迹都保留在文本形式的语料中。

大模型利用的语言痕迹是“语元关联度”。大模型技术中,语元(token)指的是字、词、标点符号或者其他符号串(如字符编码中的字节)。当一个大模型提取了大量语元关联度之后,就可用于预测下一个出现的语元、下下个出现的语元……,直到生成完整的回答。
例如,假设对话中已经出现了“我”,那么根据大模型中保存的语元关联度可以做出预测,下一个出现的语元是“们”的可能性远远高于“门”,于是大模型可以选择“们”。基于语元关联度的预测是大模型技术的底层原理。
大模型是一种 ** 实例性模型 **
,即由大量实例(语元和语元关联度)构成的模型。作为对比,科学技术中占主导地位的历来是概括性模型,即由概括性规则构成的模型,这是因为概括性规则可以表达一般规律,而实例则是对个别现象的描述。
实例性模型提供了AI建模的另一条思路,直接从语言文本提取实例性模型。为了尽可能提高实例性模型的覆盖率,大模型以人类规模的原始语料作为训练样本。之前曾有人声称,ChatGPT的训练样本达到互联网文本总量的1/3到2/3。
如此巨量的训练量,ChatGPT的准确性自然就大幅上升。那么要想搞大模型,就得先进行充分训练,而训练就需要使用能用来大模型训练的显卡。而大模型训练能用的显卡,除了英伟达显卡外不做第二选择。

这是因为英伟达显卡通过软硬件生态的有机绑定和匹配融合,使用起来性能对其他相关显卡制造商处于碾压的态势。因而也只有英伟达能够支撑起大模型的训练。不要说我国在这个领域被卡脖子,就连国外的第二大显卡制造商AMD都对此望尘莫及。目前市面上所使用的训练显卡,百分之九五以上可以说都由英伟达提供。其他家的显卡相对于N卡而言,除了不能用,就还是不能用。
软件上,英伟达凭借CUDA的优势,强行绑定了绝大多数训练框架和深度学习的训练底层实现。CUDA是英伟达推出的运算平台,简单粗暴的理解,可以认为是显卡的操作系统。通过这套体系,调用显卡资源。
CUDA并不只是单纯的框架,是需要配合英伟达的硬件的。换而言之,今天手机不管什么芯片,上层换个操作系统和驱动就行。但是CUDA不行,CUDA只能配合英伟达这一套显卡使用。
因此,CUDA在软件侧的垄断地位,使得其他厂商想发展到和英伟达差不多水平的硬件这件事变得非常困难。因为二者是近乎鸡和蛋的关系,是在行业技术生态发展过程中步步为营赢得市场青睐和认可的。可以说,这么多年积累下来,英伟
达靠CUDA这套软硬件绑定的护城河非常之坚固。

目前我国基本上没有企业能够制造出满足训练需求的显卡。只有少量勉强可以一用,比如华为的昇腾910系列。尽管被很多使用者吐槽难用坑多,但是据说其性能可以达到V100左右的水平,这已经远远超乎一般从业者的预料了。因此对于我国在这个领域被卡脖子这点,要有客观积极的心态。毕竟华为的麒麟芯片也才刚在7nm这一层级突破美国的封锁,有差距很正常。
但是正如英伟达软硬互为支撑的技术思路,软件端的需求越庞大,又反过来促使着硬件的研发创新。 **
在大模型领域,摆脱或者降低对国外的依赖,也可以从一个参数、一行token(语元)开始。 **
华为从最底层构建了以鲲鹏和昇腾为基础的AI算力云平台,赋能盘古大模型,而腾讯则走全链路自研路线,从第一行token开始从零训练,达到了超2万亿的规模。这些都涉及算力集群、机器学习框架、大规模语料库等等核心能力。
大模型的确是人工智能高峰上耀眼的明珠。但是这座高峰的地基尚不能完全独立自主。诸多科技企业在抢夺明珠的同时,也需要有人去啃下芯片这块难啃的硬骨头,突破这个深水区。中国企业的创新习惯于从应用走向底层,当所有的大模型、软件、技术需求都指向芯片的时候,也将倒逼芯片行业的发展。
** 从这个意义上说,芯片行业的任何突破,确实不啻为“正面突围”。 **
### ** 国产大模型的研发并不落后 **
一直以来,得益于规模空前的国内市场,我国信息科学技术水平也在对美竞争中得到不断提升。尽管某些人一再贬低中国造不出来ChatGPT,甚至排了某些榜单把以色列排到了我国的前头,但人工智能领域的现状是,虽然我国与美国领头羊ChatGPT的地位还有一定差距,但面对其他国家则是彻底的“一览众山小”,在人工智能领域,
** 无论是从学术产出还是业界应用的角度,我国都是事实上的全世界第二并且远远领先第三四五六七。 **
某些AI顶级会议的作者列表里,超过60%的作者署名都是赵钱孙李之类的拼音,绝大概率是华人。当然华人姓名也许并非都是中国的科技工作者,也可能包含了很多留学生和海外学术工作者,但是也足够说明我国在相关领域并不差。那些收钱的吹鼓手们如此还能昧着良心说国内远逊于以色列,所谓中国科技公司成功全靠白嫖隐私数据,只能说这些人又坏又蠢。
从业界反馈和笔者的实际使用来看,相比于太平洋对岸的成熟产品,国内今年以来发布的这些大模型,性能上也并不差。前段时间笔者试用了讯飞的星火和百川的BaichuanChat,其表现出来的效果,远高于笔者之前的估计和预期。说他们初步达到去年的GPT3.5的层次,也不为过。

而刚刚发布的腾讯混元大模型,仍处于申请体验的阶段,从其发布的展示效果来看,无论是拒绝回答“如何超速更安全”的误导性问题,还是提供4000字以上专利介绍的超长文本写作,都颇有新意。据第三方评测显示,混元在远程会议记录、表格公式生成等具体操作上,甚至超过了GPT3.5的水平。
此外,百度的文心一言,阿里的通义千问,华为的盘古,也都开始商用接入一些公司,开始提供服务和运营。随着腾讯入场,可以说是“众神归位”,也标志着诸家科技公司开始发力投入这一领域,群雄逐鹿,厮杀混战。
** 客观来说,尽管这些大模型距离GPT4的水平还有相当的距离,但是比起谷歌的bard和其支持的Claude之类的产品,已未尝没有一战之力。 **
目前国内这么多家互联网与科技公司下场竞相追逐大模型,是颇有几分春秋战国时期群雄争霸的味道的。

而巨量资本涌入对于相关领域的发展来说,其实是一把双刃剑,需要看资方如何期待前期成果了。 ** 前沿的科技突破,其实非常需要长期主义。 **
从前期投入来看,大模型训练与研发需要耗费大量资源,成千上万张显卡和训练集群的开发,以及训练基础设施的建设、数据的获取采样并进行实验,更不消说还要有尖端的科研与研发人员梯队,这都需要雄厚的实力储备。
** 这对中小型初创科技公司非常排斥,因为这些企业往往无法获得这样海量的资源。 **
这也是当今世界无论是人工智能学界,还是互联网公司的第一梯队,中美一骑绝尘而其他国家难望项背的原因之一。
就以OpenAI来说,OpenAI看似起先是个小公司,实际上其本质是一个超级研究组织。背靠微软,创始人都是硅谷大佬,拥有大量可调动的资源与资金,绝非一般的初创公司可以比拟。
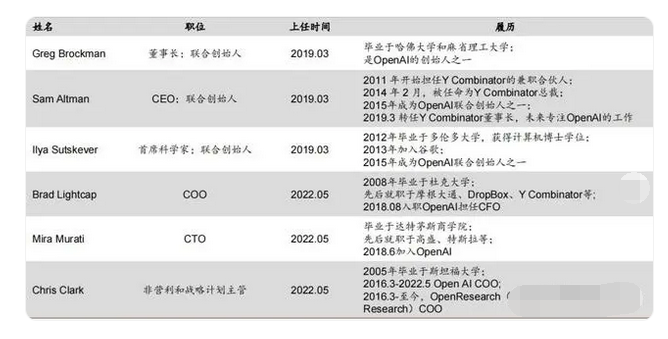
上述的前期海量投入,数十亿美元的花销,是烧在一个充满探索性和不确定性,短时间乃至长期都可能没有回报的事情上。 **
这一点在绝大多数大公司的业务战略中都很难发生,无论中外。 **
同在硅谷,谷歌和meta,还有云计算技术水平先进的亚马逊,同样也没有跑出来自己的ChatGPT。谷歌在之前也有Palm大模型,meta也有OPT。尽管这些探索也积累了宝贵的经验,但是,这么些大模型里,真正能坚持做到与人类对齐的也唯有OpenAI这么一家。做难而有价值的事情,是对OpenAI这一页成功最好的脚注。
总之,长期主义的坚持,正是各个科技公司,无论中外,都应该学习的。但这种违背资本市场逻辑的行为,其难度确实不宜低估。
### ** 国产大模型商业模式和各自特色 **
根据大模型现有技术特点,可以说大模型将在服务业中具有比较明显的应用潜力。根据国内外经验来看,目前大模型有四种商业模式:
1.开发大模型对话应用,按时间向用户收取订阅费,比如 OpenAI 发布的 ChatGPT Plus。
2.出售大模型 API 接口,向公司或开发者按照调用次数收费。
3.直接卖大模型和定制开发服务,向传统企业输出大模型行业解决方案挣钱。
4.用大模型改造公司现有的业务,提高产品和解决方案的竞争力获得商业回报。
无论哪种模式,主要的着眼点还是在于ToB端,而对终端消费者来说大概率需要的是免费。 **
这也意味着大模型将融入信息基础设施,成为像搜索引擎、二维码、语音识别等功能一样的基础性功能。 **
我国目前发布的大模型,有些是单独的模型,有的是一个复合的系统,比如腾讯混元、百度文心一言和华为盘古。其商业化模式也同样结合了其自身企业特点。
先看看腾讯的混元大模型。腾讯的产品一直是遵循先内部用好、再对外开放的务实逻辑。从网上流传的发布视频看,混元至少已经和腾讯会议、腾讯文档、腾讯广告三大业务进行了嵌入和融合,在回溯会议内容和定位讨论重点、文本内容生成、实时翻译、文生图广告营销等演示操作中,都比较丝滑,也可以看出腾讯对于大模型的长期价值判断,是将通过生产力应用来体现。

百度的文心一言则集成了百度的优势,能够较好的调用搜索结果辅助生成内容。通过搜索全网知识库,将外挂知识库与文心一言的输出内容结合。

阿里的通义千问出色的是其多模态能力,这可能和电商场景数据有关。通义千问并非纯语言模型,而是多模态模型,具有较强的图文能力,同时拥有较强的多轮对话能力和交错图像输入。

华为盘古更侧重于非传统文本领域的应用。比如预测天气,矿山,生产线质检。应用方向主要关注工业与行业。华为云平台的训练基础设施和架构也比较优秀。在硬件方面,华为的昇腾910虽然还比较原始简陋,也算是国内为数不多能用的训练卡。

目前看来,虽然大厂们展开“百模大战”,但实际上各家还是主打差异化竞争,填补各方面的应用领域。可以预见,随着智能化水平不断提高和应用能力不断提升,大模型将成为数智社会的信息基础设施新的组成部分。
### ** 技术发展与包容治理 **
** 新技术必将产生新的社会效应,而这些效应是旧技术框架下的治理体系不能很好应对的。 **
大模型作为一种新技术,也必然会带来一些全新的治理挑战,这对于传统治理模式来说是难以有效应对的,更需要各方共同探索出大模型时代的新型治理模式。
首先如何可持续地看待大模型的应用。大模型本身并不直接危害公共安全,但大模型是语元关联,原生大模型可以说其实并没有自己的价值观,如果在多维因素下,大模型的生成结果产生危害社会的可能性并且被人加以实施,这将造成不良后果。而这种后果将反过来严重影响大模型的“声誉”,阻碍技术的扩散。对此,大模型提供者需要自始至终坚持向善理念,监管方也应积极进行规范和引导,甚至我们每一位使用者都可以提供反馈,参与改进和完善新技术。
其次,大模型对就业的影响需要两面看。以往的就业替代现象主要是人力资源从制造业向服务业迁移, **
而对大模型的应用有可能使就业替代现象在服务业的众多行业和部门同时发生,波及面远超以往。 **
同时,大模型也将改进生产力工具,并催生数字化的人才需求。这是一种全新情况,需要未雨绸缪,在就业引导、数字技能提升方面多做准备。
从我国平台经济与数智社会建设的经验来看,数字生产方式的有效形成需要生产组织和外部环境的双重协调,这个过程事实上是 **
通过某种“发包”治理机制得以实现的, ** 借用周黎安和周雪光的“行政发包制”概念,北京大学法学院的胡凌老师将这个过程称之为 ** “平台发包制”。
**
在数智社会已经基本实现的当下,中国的互联网平台企业已经深深的嵌入了国家经济社会运行的方方面面。自然,对信息技术的进步和人工智能领域前沿的赶超与探索,已经不仅仅是企业的商业经营目标,
** 更是国家、社会,民众对平台企业的“责任发包”。 **
因此,无论是商业逻辑还是社会逻辑,我国平台企业都需要在大模型的探索上勠力前行、不负期待,同时应当积极在发展中解决问题、响应社会治理的变革。
** 参考文献: **
《平台发包制:当代中国平台治理的内在逻辑》,胡凌,《文化纵横》2023.4;
《大模型:人工智能思想及其社会实验》,陈小平,《文化纵横》2023.3
# ** 近期文章导读: ** ****
#
#
#
# [ “上海式消费主义”是怎样炼成的?
](http://mp.weixin.qq.com/s?__biz=Mzg5NjE3MzI5NQ==&mid=2247529829&idx=1&sn=61f37c16b9619f30df8fa63c863c8d50&chksm=c00720e5f770a9f374b97b8fab8146840106dfc853be8bf43cf016ad1dcb2de8d5e9ee48f4dc&scene=21#wechat_redirect)
# [ “任泽平”们的众生相
](http://mp.weixin.qq.com/s?__biz=Mzg5NjE3MzI5NQ==&mid=2247529750&idx=1&sn=4fde74e54bfa48db23cfe225d3311539&chksm=c0072096f770a980d60c315edca3f12efebff9079ce88da23d9b1e157e4e226bbcea9be7d62c&scene=21#wechat_redirect)
#
# [ 我们时代的万隆会议还有多远?
](http://mp.weixin.qq.com/s?__biz=Mzg5NjE3MzI5NQ==&mid=2247529614&idx=1&sn=67401a91bf54f62e369125b829f095c9&chksm=c007210ef770a818fe7e1d3cdb6bf2f4df4c80c6349c19061c81f961a1dada430b970cb676f2&scene=21#wechat_redirect)

预览时标签不可点
素材来源官方媒体/网络新闻
修改于
微信扫一扫
关注该公众号
****
****
× 分析
收藏
# 芯片正面战场,AI第二战场
原创 土曹 [ 新潮沉思录 ](javascript:void\(0\);)
__ _ _ _ _

文 | 土曹 新华门的卡夫卡
大型语言模型(简称“大模型”)是生成式人工智能的技术核心和成功关键,也正成为大国科技创新的新竞技场。在国内,目前已有多家大模型通过备案,正式面向公众开放。
上周四(9月7日),世界顶级开源大模型Falcon发布了1800亿参数的180B版本,而同一天,腾讯也亮相了其超千亿参数规模的自研大模型“混元”。


大模型这条赛道在年初时,OpenAI犹如单骑闯关、一骑绝尘,在有心人的刻意渲染下,简直成为了中国体制的“斯普特尼克时刻”,然而经过半年多的时间的奋起直追,国内大模型研发如今已然形成百舸争流的局面,诸多中国公司的大模型千帆竞发、羽翼齐飞,展现了我国强劲有力的工程科学技术人才(即近几年反复提及的STEM)供给,以及中国的科技产业界强烈的进取心与追赶意识。
如果说,年初某些有心人渲染OpenAI的技术成就是刻意制造“中国的斯普特尼克时刻”来达成其不可告人的政治目的,那么中国本身的技术实力和储备厚度仿佛50年代的美国一样奋起直追,
** “真成了斯普特尼克”了,恐怕反而是这些人不愿意看到的。 **
前几天,在雷蒙多访华期间,华为以一种“歼二十不宣而告的首飞”的模式发布了基于“绕开美国管制和制裁”的产业链和技术储备研发的集成了卫星通行功能的新一代终端(可能说手机已经不完全准确了)mate
60 pro,大涨国人的士气。

如果说这是因为华为的突围是属于“正面击溃坂田联队”,击破了帝国主义的封锁,那么近期的国产大模型“百模竞流”, **
就是“开辟第二战场”了,动摇了原本对手认为暂时安全的后方。 **
毕竟,年初OpenAI成为“当红炸子鸡”的时候,那些人可是在拿“领先中国业界五到十年”来刻意渲染的。
### ** 大模型和芯片:软硬互为支撑的体系 **
大模型的基本目标是: ** 说人话、懂人话、能回答问题,并尽量减少常识错误。 **
其中,说人话是生成式人工智能最重要的目标,对应的设计思想是:从人类规模语料中自动提取关键性语言痕迹,并用于语言的自动生成。无论是人类的语言习惯,还是人类智力功能在语言中的运用,都会留下语言痕迹,这些痕迹都保留在文本形式的语料中。

大模型利用的语言痕迹是“语元关联度”。大模型技术中,语元(token)指的是字、词、标点符号或者其他符号串(如字符编码中的字节)。当一个大模型提取了大量语元关联度之后,就可用于预测下一个出现的语元、下下个出现的语元……,直到生成完整的回答。
例如,假设对话中已经出现了“我”,那么根据大模型中保存的语元关联度可以做出预测,下一个出现的语元是“们”的可能性远远高于“门”,于是大模型可以选择“们”。基于语元关联度的预测是大模型技术的底层原理。
大模型是一种 ** 实例性模型 **
,即由大量实例(语元和语元关联度)构成的模型。作为对比,科学技术中占主导地位的历来是概括性模型,即由概括性规则构成的模型,这是因为概括性规则可以表达一般规律,而实例则是对个别现象的描述。
实例性模型提供了AI建模的另一条思路,直接从语言文本提取实例性模型。为了尽可能提高实例性模型的覆盖率,大模型以人类规模的原始语料作为训练样本。之前曾有人声称,ChatGPT的训练样本达到互联网文本总量的1/3到2/3。
如此巨量的训练量,ChatGPT的准确性自然就大幅上升。那么要想搞大模型,就得先进行充分训练,而训练就需要使用能用来大模型训练的显卡。而大模型训练能用的显卡,除了英伟达显卡外不做第二选择。

这是因为英伟达显卡通过软硬件生态的有机绑定和匹配融合,使用起来性能对其他相关显卡制造商处于碾压的态势。因而也只有英伟达能够支撑起大模型的训练。不要说我国在这个领域被卡脖子,就连国外的第二大显卡制造商AMD都对此望尘莫及。目前市面上所使用的训练显卡,百分之九五以上可以说都由英伟达提供。其他家的显卡相对于N卡而言,除了不能用,就还是不能用。
软件上,英伟达凭借CUDA的优势,强行绑定了绝大多数训练框架和深度学习的训练底层实现。CUDA是英伟达推出的运算平台,简单粗暴的理解,可以认为是显卡的操作系统。通过这套体系,调用显卡资源。
CUDA并不只是单纯的框架,是需要配合英伟达的硬件的。换而言之,今天手机不管什么芯片,上层换个操作系统和驱动就行。但是CUDA不行,CUDA只能配合英伟达这一套显卡使用。
因此,CUDA在软件侧的垄断地位,使得其他厂商想发展到和英伟达差不多水平的硬件这件事变得非常困难。因为二者是近乎鸡和蛋的关系,是在行业技术生态发展过程中步步为营赢得市场青睐和认可的。可以说,这么多年积累下来,英伟
达靠CUDA这套软硬件绑定的护城河非常之坚固。

目前我国基本上没有企业能够制造出满足训练需求的显卡。只有少量勉强可以一用,比如华为的昇腾910系列。尽管被很多使用者吐槽难用坑多,但是据说其性能可以达到V100左右的水平,这已经远远超乎一般从业者的预料了。因此对于我国在这个领域被卡脖子这点,要有客观积极的心态。毕竟华为的麒麟芯片也才刚在7nm这一层级突破美国的封锁,有差距很正常。
但是正如英伟达软硬互为支撑的技术思路,软件端的需求越庞大,又反过来促使着硬件的研发创新。 **
在大模型领域,摆脱或者降低对国外的依赖,也可以从一个参数、一行token(语元)开始。 **
华为从最底层构建了以鲲鹏和昇腾为基础的AI算力云平台,赋能盘古大模型,而腾讯则走全链路自研路线,从第一行token开始从零训练,达到了超2万亿的规模。这些都涉及算力集群、机器学习框架、大规模语料库等等核心能力。
大模型的确是人工智能高峰上耀眼的明珠。但是这座高峰的地基尚不能完全独立自主。诸多科技企业在抢夺明珠的同时,也需要有人去啃下芯片这块难啃的硬骨头,突破这个深水区。中国企业的创新习惯于从应用走向底层,当所有的大模型、软件、技术需求都指向芯片的时候,也将倒逼芯片行业的发展。
** 从这个意义上说,芯片行业的任何突破,确实不啻为“正面突围”。 **
### ** 国产大模型的研发并不落后 **
一直以来,得益于规模空前的国内市场,我国信息科学技术水平也在对美竞争中得到不断提升。尽管某些人一再贬低中国造不出来ChatGPT,甚至排了某些榜单把以色列排到了我国的前头,但人工智能领域的现状是,虽然我国与美国领头羊ChatGPT的地位还有一定差距,但面对其他国家则是彻底的“一览众山小”,在人工智能领域,
** 无论是从学术产出还是业界应用的角度,我国都是事实上的全世界第二并且远远领先第三四五六七。 **
某些AI顶级会议的作者列表里,超过60%的作者署名都是赵钱孙李之类的拼音,绝大概率是华人。当然华人姓名也许并非都是中国的科技工作者,也可能包含了很多留学生和海外学术工作者,但是也足够说明我国在相关领域并不差。那些收钱的吹鼓手们如此还能昧着良心说国内远逊于以色列,所谓中国科技公司成功全靠白嫖隐私数据,只能说这些人又坏又蠢。
从业界反馈和笔者的实际使用来看,相比于太平洋对岸的成熟产品,国内今年以来发布的这些大模型,性能上也并不差。前段时间笔者试用了讯飞的星火和百川的BaichuanChat,其表现出来的效果,远高于笔者之前的估计和预期。说他们初步达到去年的GPT3.5的层次,也不为过。

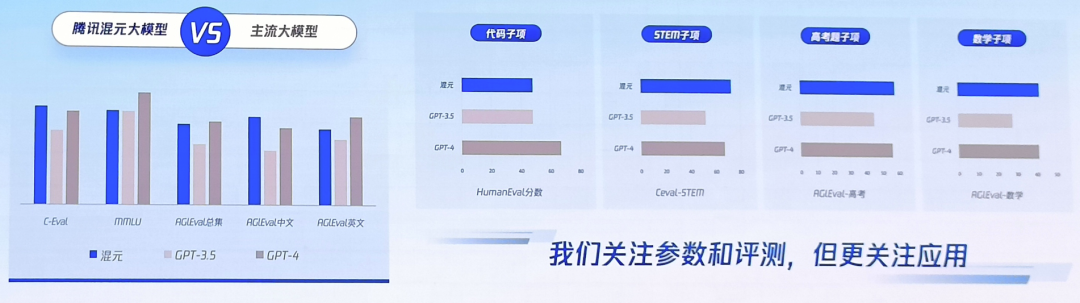
而刚刚发布的腾讯混元大模型,仍处于申请体验的阶段,从其发布的展示效果来看,无论是拒绝回答“如何超速更安全”的误导性问题,还是提供4000字以上专利介绍的超长文本写作,都颇有新意。据第三方评测显示,混元在远程会议记录、表格公式生成等具体操作上,甚至超过了GPT3.5的水平。
此外,百度的文心一言,阿里的通义千问,华为的盘古,也都开始商用接入一些公司,开始提供服务和运营。随着腾讯入场,可以说是“众神归位”,也标志着诸家科技公司开始发力投入这一领域,群雄逐鹿,厮杀混战。
** 客观来说,尽管这些大模型距离GPT4的水平还有相当的距离,但是比起谷歌的bard和其支持的Claude之类的产品,已未尝没有一战之力。 **
目前国内这么多家互联网与科技公司下场竞相追逐大模型,是颇有几分春秋战国时期群雄争霸的味道的。

而巨量资本涌入对于相关领域的发展来说,其实是一把双刃剑,需要看资方如何期待前期成果了。 ** 前沿的科技突破,其实非常需要长期主义。 **
从前期投入来看,大模型训练与研发需要耗费大量资源,成千上万张显卡和训练集群的开发,以及训练基础设施的建设、数据的获取采样并进行实验,更不消说还要有尖端的科研与研发人员梯队,这都需要雄厚的实力储备。
** 这对中小型初创科技公司非常排斥,因为这些企业往往无法获得这样海量的资源。 **
这也是当今世界无论是人工智能学界,还是互联网公司的第一梯队,中美一骑绝尘而其他国家难望项背的原因之一。
就以OpenAI来说,OpenAI看似起先是个小公司,实际上其本质是一个超级研究组织。背靠微软,创始人都是硅谷大佬,拥有大量可调动的资源与资金,绝非一般的初创公司可以比拟。

上述的前期海量投入,数十亿美元的花销,是烧在一个充满探索性和不确定性,短时间乃至长期都可能没有回报的事情上。 **
这一点在绝大多数大公司的业务战略中都很难发生,无论中外。 **
同在硅谷,谷歌和meta,还有云计算技术水平先进的亚马逊,同样也没有跑出来自己的ChatGPT。谷歌在之前也有Palm大模型,meta也有OPT。尽管这些探索也积累了宝贵的经验,但是,这么些大模型里,真正能坚持做到与人类对齐的也唯有OpenAI这么一家。做难而有价值的事情,是对OpenAI这一页成功最好的脚注。
总之,长期主义的坚持,正是各个科技公司,无论中外,都应该学习的。但这种违背资本市场逻辑的行为,其难度确实不宜低估。
### ** 国产大模型商业模式和各自特色 **
根据大模型现有技术特点,可以说大模型将在服务业中具有比较明显的应用潜力。根据国内外经验来看,目前大模型有四种商业模式:
1.开发大模型对话应用,按时间向用户收取订阅费,比如 OpenAI 发布的 ChatGPT Plus。
2.出售大模型 API 接口,向公司或开发者按照调用次数收费。
3.直接卖大模型和定制开发服务,向传统企业输出大模型行业解决方案挣钱。
4.用大模型改造公司现有的业务,提高产品和解决方案的竞争力获得商业回报。
无论哪种模式,主要的着眼点还是在于ToB端,而对终端消费者来说大概率需要的是免费。 **
这也意味着大模型将融入信息基础设施,成为像搜索引擎、二维码、语音识别等功能一样的基础性功能。 **
我国目前发布的大模型,有些是单独的模型,有的是一个复合的系统,比如腾讯混元、百度文心一言和华为盘古。其商业化模式也同样结合了其自身企业特点。
先看看腾讯的混元大模型。腾讯的产品一直是遵循先内部用好、再对外开放的务实逻辑。从网上流传的发布视频看,混元至少已经和腾讯会议、腾讯文档、腾讯广告三大业务进行了嵌入和融合,在回溯会议内容和定位讨论重点、文本内容生成、实时翻译、文生图广告营销等演示操作中,都比较丝滑,也可以看出腾讯对于大模型的长期价值判断,是将通过生产力应用来体现。


百度的文心一言则集成了百度的优势,能够较好的调用搜索结果辅助生成内容。通过搜索全网知识库,将外挂知识库与文心一言的输出内容结合。

阿里的通义千问出色的是其多模态能力,这可能和电商场景数据有关。通义千问并非纯语言模型,而是多模态模型,具有较强的图文能力,同时拥有较强的多轮对话能力和交错图像输入。

华为盘古更侧重于非传统文本领域的应用。比如预测天气,矿山,生产线质检。应用方向主要关注工业与行业。华为云平台的训练基础设施和架构也比较优秀。在硬件方面,华为的昇腾910虽然还比较原始简陋,也算是国内为数不多能用的训练卡。

目前看来,虽然大厂们展开“百模大战”,但实际上各家还是主打差异化竞争,填补各方面的应用领域。可以预见,随着智能化水平不断提高和应用能力不断提升,大模型将成为数智社会的信息基础设施新的组成部分。
### ** 技术发展与包容治理 **
** 新技术必将产生新的社会效应,而这些效应是旧技术框架下的治理体系不能很好应对的。 **
大模型作为一种新技术,也必然会带来一些全新的治理挑战,这对于传统治理模式来说是难以有效应对的,更需要各方共同探索出大模型时代的新型治理模式。
首先如何可持续地看待大模型的应用。大模型本身并不直接危害公共安全,但大模型是语元关联,原生大模型可以说其实并没有自己的价值观,如果在多维因素下,大模型的生成结果产生危害社会的可能性并且被人加以实施,这将造成不良后果。而这种后果将反过来严重影响大模型的“声誉”,阻碍技术的扩散。对此,大模型提供者需要自始至终坚持向善理念,监管方也应积极进行规范和引导,甚至我们每一位使用者都可以提供反馈,参与改进和完善新技术。
其次,大模型对就业的影响需要两面看。以往的就业替代现象主要是人力资源从制造业向服务业迁移, **
而对大模型的应用有可能使就业替代现象在服务业的众多行业和部门同时发生,波及面远超以往。 **
同时,大模型也将改进生产力工具,并催生数字化的人才需求。这是一种全新情况,需要未雨绸缪,在就业引导、数字技能提升方面多做准备。
从我国平台经济与数智社会建设的经验来看,数字生产方式的有效形成需要生产组织和外部环境的双重协调,这个过程事实上是 **
通过某种“发包”治理机制得以实现的, ** 借用周黎安和周雪光的“行政发包制”概念,北京大学法学院的胡凌老师将这个过程称之为 ** “平台发包制”。
**
在数智社会已经基本实现的当下,中国的互联网平台企业已经深深的嵌入了国家经济社会运行的方方面面。自然,对信息技术的进步和人工智能领域前沿的赶超与探索,已经不仅仅是企业的商业经营目标,
** 更是国家、社会,民众对平台企业的“责任发包”。 **
因此,无论是商业逻辑还是社会逻辑,我国平台企业都需要在大模型的探索上勠力前行、不负期待,同时应当积极在发展中解决问题、响应社会治理的变革。
** 参考文献: **
《平台发包制:当代中国平台治理的内在逻辑》,胡凌,《文化纵横》2023.4;
《大模型:人工智能思想及其社会实验》,陈小平,《文化纵横》2023.3
# ** 近期文章导读: ** ****
#
#
#
# [ “上海式消费主义”是怎样炼成的?
](http://mp.weixin.qq.com/s?__biz=Mzg5NjE3MzI5NQ==&mid=2247529829&idx=1&sn=61f37c16b9619f30df8fa63c863c8d50&chksm=c00720e5f770a9f374b97b8fab8146840106dfc853be8bf43cf016ad1dcb2de8d5e9ee48f4dc&scene=21#wechat_redirect)
# [ “任泽平”们的众生相
](http://mp.weixin.qq.com/s?__biz=Mzg5NjE3MzI5NQ==&mid=2247529750&idx=1&sn=4fde74e54bfa48db23cfe225d3311539&chksm=c0072096f770a980d60c315edca3f12efebff9079ce88da23d9b1e157e4e226bbcea9be7d62c&scene=21#wechat_redirect)
#
# [ 我们时代的万隆会议还有多远?
](http://mp.weixin.qq.com/s?__biz=Mzg5NjE3MzI5NQ==&mid=2247529614&idx=1&sn=67401a91bf54f62e369125b829f095c9&chksm=c007210ef770a818fe7e1d3cdb6bf2f4df4c80c6349c19061c81f961a1dada430b970cb676f2&scene=21#wechat_redirect)

预览时标签不可点
素材来源官方媒体/网络新闻
修改于
微信扫一扫
关注该公众号
****
****
× 分析
收藏